Operator Capability Levels
Operators come in different maturity levels in regards to their lifecycle management capabilities for the application or workload they deliver. The capability models aims to provide guidance in terminology to express what features users can expect from an operator.
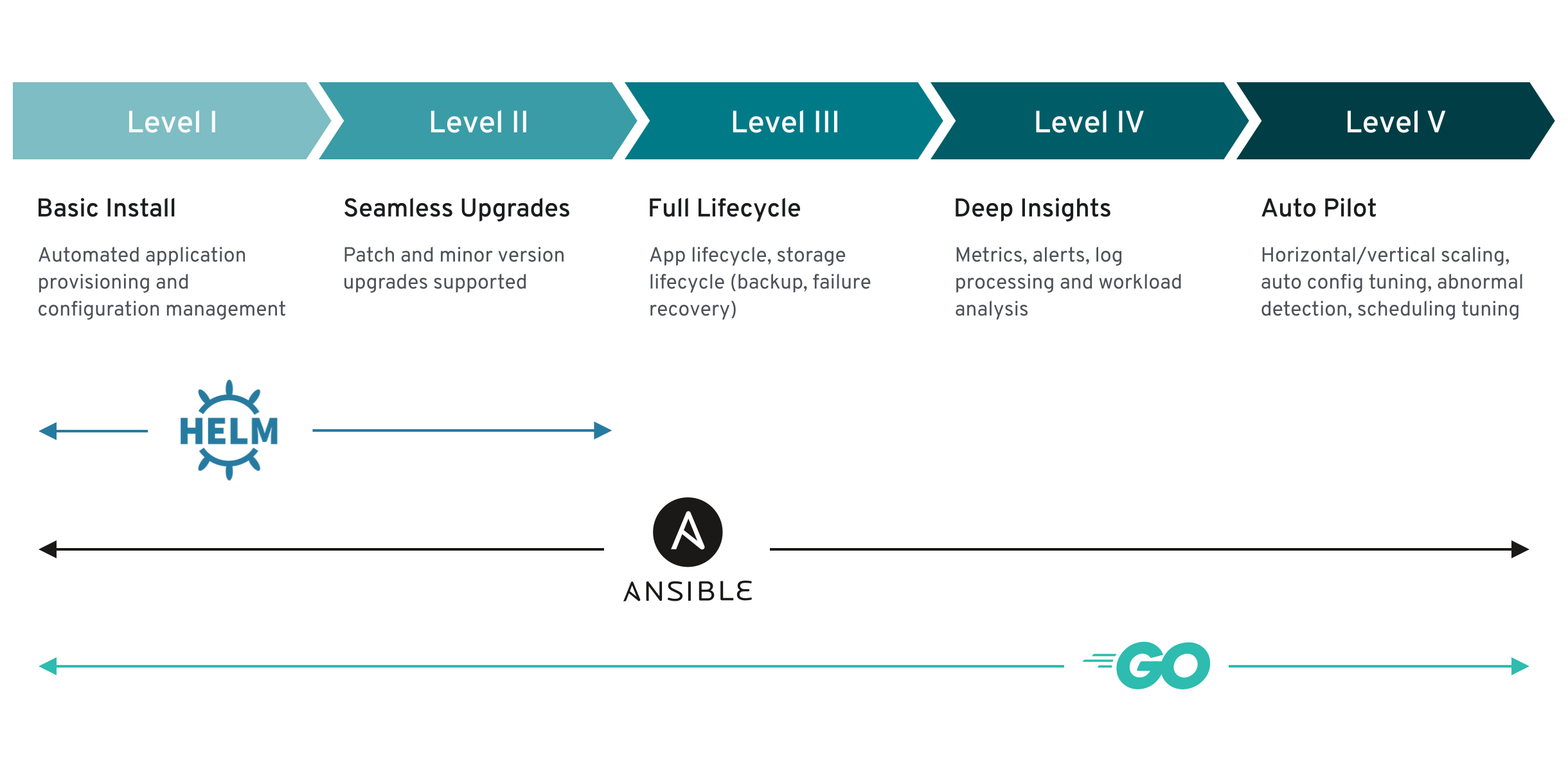
Each capability level is associated with a certain set of management features the Operator offers around the managed workload. Operator that do not manage a workload and/or are delegating to off-clusters orchestration services would remain at Level 1. Capability levels are accumulating, i.e. Level 3 capabilities require all capabilities desired from Level 1 and 2.
Terminology
Operator - the custom controller installed on a Kubernetes cluster
Operand - the managed workload provided by the Operator as a service
Custom Resource (CR) - an instance of the CustomResourceDefinition the Operator ships that represents the Operand or an Operation on an Operand (also known as primary resources)
Managed resources - the Kubernetes objects or off-cluster services the Operator uses to constitute an Operand (also known as secondary resources)
Custom Resource Definition (CRD) - an API of the Operator, providing the blueprint and validation rules for Custom Resources.
Level 1 - Basic Install
Automated application provisioning and configuration management. This first capability level means your operator can fully provision an application through a custom resource, allowing all installation configuration details to be specified in the CR. It should also be possible to install the operator itself in multiple ways (kubectl, OLM, Catalog source). Any configuration required to make the Operand run should be configured through the CR if possible. Avoid the practice of requiring the user to create/manage configuration files outside of Kubernetes.
Installation of the workload
- Operator deploys an Operand or configures off-cluster resources
- Operator waits for managed resources to reach a healthy state
- Operator conveys readiness of application or managed resources to the user leveraging the
statusblock of the Custom Resource
Example: an Operator deploys a database by creating Deployment, ServiceAccount, RoleBinding, ConfigMap, PersistentVolumeClaim and Secret object, initializes an empty database schema and signals readiness of the database to accept queries.
Configuration of the workload
- Operator provides configuration via the
specsection of the Custom Resource - Operator reconciles configuration and updates to it with the status of the managed resources
Example: an Operator, managing a database, offers increasing the capacity of the database by resizing the underlying PersistentVolumeClaim based on changes the databases Custom Resource instance.
Guiding questions to determine Operator reaching Level 1
-
What installation configuration can be set in the CR?
-
What additional installation configuration could still be added?
-
Can you set operand configuration in the CR? If so, what configuration is supported for each operand?
-
Can you override the operand images through the CR or an environment variable of the Operator deployment?
-
Does the managed application / workload get updated in a non-disruptive fashion when the configuration of the CR is changed?
-
Does the status of the CR reflect that configuration changes are currently applied?
-
What additional operand configuration could still be added?
-
Do all of the instantiated CRs include a status block? If so, does it provide enough insight to the user about the application state?
-
Do all of your CRs have documentation listing valid values and mandatory fields?
-
If your operator is packaged for OLM, does its CSV list all images used in the CSV under
spec.relatedImages?
Level 2 - Seamless Upgrades
Seamless upgrades mean the upgrade is as easy as possible for the user. You should support seamless upgrades of both your operator and operand, these would normally go hand in hand, an upgrade of the operator would automatically ensure the instantiated resources for each CR are in the new desired state and which would upgrade your operand. Upgrade may also be defined in multiple ways, such as updating the software of the operand - and other internals specific to the application - such as schema migrations. It should be very clear what is upgraded when this takes place, and what is not.
Upgrade of the managed workload
- Operand can be upgraded in the process of upgrading the Operator, or
- Operand can be upgraded as part of changing the CR
- Operator understands how to upgrade older versions of the Operand, managed previously by an older version of the Operator
Upgrade of the Operator
- Operator can be upgraded seamlessly and can either still manage older versions of the Operand or update them
- Operator conveys inability to manage an unsupported version of the Operand in the
statussection of the CR
Example: An Operator managing a database can update an existing database from a previous to a newer version without data loss. The Operator might do so as part of a configuration change or as part of an update of the Operator itself.
Guiding questions to determine Operator reaching Level 2
-
Can your Operator upgrade your Operand?
-
Does your Operator upgrade your Operand during updates of the Operator?
-
Can your Operator manage older Operand version versions?
-
Is the Operand upgrade non disruptive?
-
If there is downtime during an upgrade, does the Operator convey this in the
statusof the CR?
Level 3 - Full Lifecycle
It should be possible to backup and restore the operand from the operator itself without any additional manual intervention other than triggering these operations. The operand data that should be backed up is any stateful data managed by the operand. You don’t need to backup the CR itself or the k8s resources created by the operator as the operator should return all resources to the same state if the CR is recreated. If your operator does not already setup the operand with other k8s resilient best practices, this should be completed to achieve this capability level. This includes liveness and readiness probes, multiple replicas, rolling deployment strategies, pod disruption budgets, CPU and memory requests and limits.
Lifecycle features
- Operator provides the ability to create backups of the Operand
- Operator is able to restore a backup of an Operand
- Operator orchestrates complex re-configuration flows on the Operand
- Operator implements fail-over and fail-back of clustered Operands
- Operator supports add/removing members to a clustered Operand
- Operator enables application-aware scaling of the Operand
Example: an Operator managing a database provides the ability to create an application consistent backup of the data by flushing the database log and quiescing the write activity to the database files.
Guiding questions to determine Operator reaching Level 3
-
Does your Operator support backing up the Operand?
-
Does your Operator support restoring an Operand from a backup and get it under management again?
-
Does your Operator wait for reconfiguration work to be finished and in the expected sequence?
-
Is your Operator taking cluster quorum into account, if present?
-
Does your Operator allow adding/removing read-only slave instances of your Operator?
-
Does your operand have a Liveness probe?
-
Does your operand have a Readiness probe which will fail if any aspect of the operand is not ready? e.g. if the connection to the database fails.
-
Does your operand use a rolling deployment strategy?
-
Does your operator create a PodDisruptionBudget resource for your operand pods?
-
Does your operand have CPU requests and limits set?
Level 4 - Deep Insights
Setup full monitoring and alerting for your operand. All resources such as Prometheus rules (alerts) and Grafana dashboards should be created by the operator when the operand CR is instantiated. The RED method1 is a good place to start with knowing what metrics to expose. Aim to have as few alerts as possible, by alerting on symptoms that are associated with end-user pain rather than trying to catch every possible way that pain could be caused. Alerts should link to relevant consoles and make it easy to figure out which component is at fault Native k8s objects emit events (“Events” objects) for situations users or administrators should be alerted about. Your operator should do similar for state changes related to your operand. “Custom”, here, means that it should emit events specific to your operator/operand outside of the events already emitted by their deployment methodology. This, in conjunction with status descriptors for the CR conditions, give much needed visibility into actions taken by your operator/operand. Operators are codified domain-specific knowledge. Your end user should not need this domain-specific knowledge to gain visibility into what’s happening with their resource. Please, ensure that you look at the Kubernetes API conventions in the Events and status sections to know how to properly deal with them.
Monitoring
- Operator exposing metrics about its health
- Operator exposes health and performance metrics about the Operand
Alerting and Events
- Operand sends useful alerts
- Custom Resources emit custom events
Example: A database Operator continues to parse the logging output of the database software and understands noteworthy log events, e.g. running out of space for database files and produces alerts. The operator also instruments the database and exposes application level, e.g. database queries per second
Guiding questions to determine Operator reaching Level 4
-
Does your Operator expose a health metrics endpoint?
-
Does your Operator expose Operand alerts?
-
Do you have Standard Operating Procedures (SOPs) for each alert?
-
Does you operator create critical alerts when the service is down and warning alerts for all other alerts?
-
Does your Operator watch the Operand to create alerts?
-
Does your Operator emit custom Kubernetes events?
-
Does your Operator expose Operand performance metrics?
1 The RED method The RED Method defines the three key metrics for every service in your architecture.
- Rate (the number of requests per second)
- Errors (the number of those requests that are failing)
- Duration (the amount of time those requests take)
Note that by building projects using Operator-SDK or Kubebuilder CLI tools your solution leverages controller-runtime which provides the following reference exported by default. For further information, see the metrics documentation to understand how to enable monitoring and add custom metrics . Also, you may want to give a look at the (grafana/v1-alpha) which provides some JSON manifests to create Grafana dashboards using the default metrics exported.
Level 5 - Auto Pilot
The highest capability level aims to significantly reduce/eliminate any remaining manual intervention in managing the operand. The operator should configure the Operand to auto-scale as load picks up. The Operator should understand the application-level performance indicators and determine when it’s healthy and performing well. The operator should attempt to automatically fix an unhealthy operand. The operator should tune the operands performance, this could include scheduling on another node the pods are running on or modifying operand configuration.
Auto-scaling
- Operator scales the Operand up under increased load based on Operand metric
- Operator scales the Operand down below a certain load based on Operand metric
Auto-Healing
- Operator can automatically heal unhealthy Operands based on Operand metrics/alerts/logs
- Operator can prevent the Operand from transitioning into an unhealthy state based on Operand metrics
Auto-tuning
- Operator is able to automatically tune the Operand to a certain workload pattern
- Operator dynamically shifts workloads onto best suited nodes
Abnormality detection
- Operator determines deviations from a standard performance profile
Example: A database operator monitors the query load of the database and automatically scales additional read-only slave replicas up and down. The operator also detects subpar index performance and automatically rebuilds the index in times of reduced load. Further, the operator understands the normal performance profile of the database and creates alerts on excessive amount of slow queries. In the event of slow queries and high disk latency the Operator automatically transitions the database files to another PersistentVolume of a higher performance class.
Guiding questions to determine Operator reaching Level 5
-
Can your operator read metrics such as requests per second or other relevant metrics and auto-scale horizontally or vertically, i.e., increasing the number of pods or resources used by pods?
-
Based on question number 1 can it scale down or decrease the number of pods or the total amount of resources used by pods?
-
Based on the deep insights built upon level 4 capabilities can your operator determine when an operand became unhealthy and take action such as redeploying, changing configurations, restoring backups etc.?
-
Again considering that with level 4 deep insights the operator has information to learn the performance baseline dynamically and can learn the best configurations for peak performance can it adjust the configurations to do so?
-
Can it move the workloads to better nodes, storage or networks to do so?
-
Can it detect and alert when anything is working below the learned performance baseline that can’t be corrected automatically?